6
里程碑 #2
我们获得了不同机器配置下的每秒请求数上限,现在我们仅剩下前面提到的一个任务:达到生产环境的3倍负载
- 每秒请求数900
- TCP连接数2.1m
- 网络带宽30MB/s
我们再次在达到220k个TCP连接数上受阻。无论怎么设置休眠时间,TCP连接数就是无法再上升。
让我们来计算下,220k个TCP连接和每秒请求数900,110,000 / 900 ~= 120秒。这里使用110k因为220k个连接同时包含了输入和输出,既双向总数。
这让我们怀疑2分钟是系统某处的一个限制,通过查看HAProxy日志可以验证,日志中大部分连接的总耗时都在120000毫秒。
Mar 23 13:24:24 localhost haproxy[53750]: 172.168.0.232:48380
[23/Mar/2017:13:22:22.686] api~ api-backend/http31 39/0/2062/-1/122101
-1 0 - - SD-- 1714/1714/1678/35/0 0/0 {0,"",""}
"POST /ping HTTP/1.1"其中122101是总处理时长。日志中所有字段详细值参见HAProxy文档。
经过进一步研究,我们发现Node.js有2分钟的默认超时时间。
具体信息参见下面一些资料:
解决了超时时间之后,事情并没有想象中的顺利。当连接数达到1.3m个时,HAProxy连接数突然下降到0,然后再次开始上升。通过dmesg命令查看内核日志之后发现,该现象是系统内存不足造成的。通过更换成16核64GB内存,并设置nbproc = 3之后,最终达到了2.4m个连接。
后端代码
下面是HAProxy后端服务的源码。我们在代码中使用了statsd库,以获取服务端每秒请求数。
var http = require('http');
var createStatsd = require('uber-statsd-client');
qs = require('querystring');
var sdc = createStatsd({
host: '172.168.0.134',
port: 8125
});
var argv = process.argv;
var port = argv[2];
function randomIntInc (low, high)
{
return Math.floor(Math.random() * (high - low + 1) + low);
}
function sendResponse(res,times, old_sleep)
{
res.write('pong');
if(times==0)
{
res.end();
}
else
{
sleep = randomIntInc(0, old_sleep+1);
setTimeout(sendResponse, sleep, res,times-1, old_sleep);
}
}
var server = http.createServer(function(req, res)
{
headers = req.headers;
old_sleep = parseInt(headers["sleep"]);
times = headers["times"] || 0;
sleep = randomIntInc(0, old_sleep+1);
console.log(sleep);
sdc.increment("ssl.server.http");
res.writeHead(200);
setTimeout(sendResponse, sleep, res, times, old_sleep)
});
server.timeout = 3600000;
server.listen(port);同时我们还有一个小脚本来运行多个后端服务。整个测试中,我们使用了8台服务器,每台服务器上运行了10个后端服务进程,以避免后端服务称为压力测试的瓶颈。
counter=0 while [ $counter -le 9 ] do port=$((8282+$counter)) nodejs /opt/local/share/test-tools/HikeCLI/nodeclient/httpserver.js $port & echo "Server created on port " $port ((counter++)) done echo "Created all servers"
客户端代码
对于客户端,每个IP有63k个TCP连接的限制。如果对此不了解,参见本系列的前面一篇文章。
因此为了达到2.4m个连接(双向连接,对于客户端来说要发起1.2m个连接),我们需要大约20台机器。在所有20台机器上同时运行Vegeta命令非常痛苦,即使使用了类似csshx工具,仍然需要从所有Vegeta合并最终测试结果。
脚本如下:
result_file=$1
declare -a machines=("172.168.0.138" "172.168.0.141
" "172.168.0.142" "172.168.0.18" "
172.168.0.5" "172.168.0.122" "172.168.0.123" "
172.168.0.124" "172.168.0.232" " 172.168.0.24
4" "172.168.0.170" "172.168.0.179" "
172.168.0.59" "172.168.0.68" "172.168.0.137" "
;172.168.0.155" "172.168.0.154" "172.168.0.45" "
172.168.0.136" "172.168.0.143")
bins=""
commas=""
for i in "${machines[@]}"; do bins=$bins","$i".
bin"; commas=$commas","$i; done;
bins=${bins:1}
commas=${commas:1}
pdsh -b -w "$commas" 'echo "POST
http://test.haproxy.in:80/ping" | /home/sachinm/.linuxbrew/bin/vegeta -cpus=32
attack -connections=1000000 -header="sleep:20" -header="
times:2" -body=post_smaller.txt -timeout=2h -rate=3000 -workers=
500 > ' $result_file for i in "${machines[@]}"; do scp sachinm
@$i:/home/sachinm/$result_file $i.bin ; done;
vegeta report -inputs="$bins"幸好这里使用了pdsh工具,使得我们能够在多台远程服务器上并行的执行命令。同时Vegeta也提供了结果合并功能,这也是我们急需的。
HAProxy配置
本节大概是读者最希望了解的内容,下面是我们在压力测试场景中使用的HAProxy配置。其中最重要的部分是nbproc和maxconn设置。其中maxconn设置允许HAProxy能够支持我们期望达到的TCP连接数。
maxconn 设置会影响HAProxy进程的ulimit,例如:
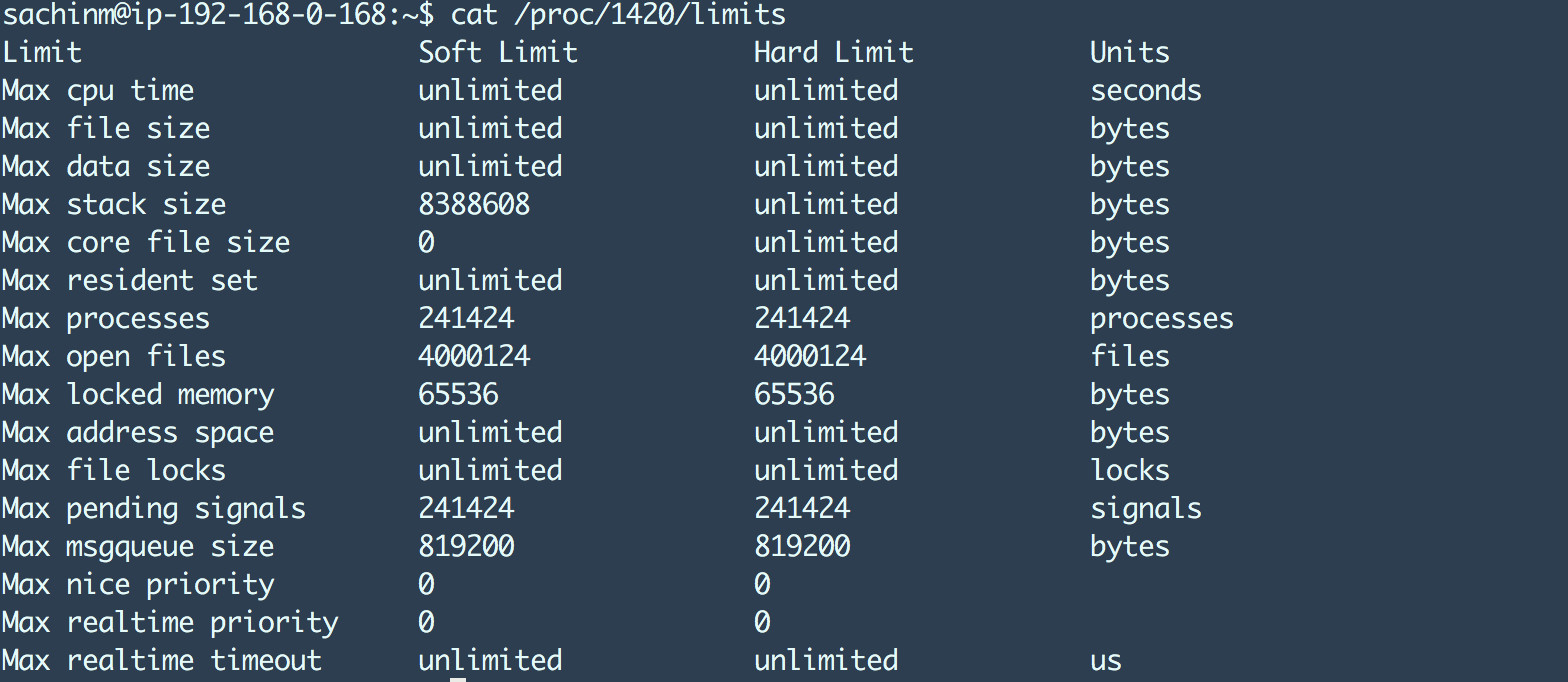
最大文件打开数设置到4m因为HAProxy的最大连接数设置成了2m。干净利落!